Replication of Tadesse et al. (2019)
This project reproduces the study “Detection of Depression-Related Posts in Reddit Social Media Forum”. Using scraped Reddit data and a mixture of linguistic feature sets, the goal is to classify whether a post is depression‑related.
Overview
The original paper built models using Empath psycholinguistic features, n‑gram frequencies, and LDA topic distributions. My replication follows the same steps and compares results; differences are discussed in the accompanying PDF.
Workflow
- Data preprocessing: raw posts were scraped from r/depression, r/breastcancer and other subreddits; text cleaned by removing usernames, punctuation and stopwords.
- Feature extraction: extracted unigram/ bigram counts, Empath category scores, and LDA topic vectors.
- Feature analysis: generated word clouds, correlation tables and TSNE plots to inspect the feature spaces.
- Model training: trained SVM and random forest classifiers; evaluated with accuracy, F1, precision and recall.
- Testing: unit tests cover preprocessing, extraction and training functions to ensure reproducibility.
Repository structure
- data/ raw, preprocessed, and feature datasets.
- data_preprocessing/ scraping and cleaning scripts.
- feature_extraction/ implementations for n‑grams, Empath and LDA.
- feature_analysis/ visualization scripts (word clouds, TSNE, etc).
- model_training/ training and evaluation code.
- test/ pytest suites for each component.
Skills showcased
Key findings
- Above‑chance classification was achieved; Empath features performed best, consistent with the original study.
- N‑gram models provided a strong baseline, while LDA topics were weaker predictors.
- Reproduction highlighted how preprocessing choices and dataset updates can shift results.
- Automated tests and clear directory layout made the replication process reasonably smooth.
Model performance comparison
The table compares classification accuracy from Tadesse et al. (2019) with this replication. It focuses on SVM results for direct comparability, though AdaBoost and other models also performed strongly. Note: the original paper used LIWC2015 to categorize words into psycholinguistic categories, while this replication used Empath as a comparable alternative.
| Feature set | Original accuracy | Replication accuracy |
|---|---|---|
| Empath | 0.74 | 0.6819 |
| Latent Dirichlet Allocation (LDA) | 0.72 | 0.7073 |
| Unigrams | 0.70 | 0.9255 |
| Bigrams | 0.80 | 0.6819 |
| Empath + LDA + Unigrams | 0.79 | 0.9188 |
| Empath + LDA + Bigrams | 0.90 | 0.9966 |
Feature visualizations highlight lexical differences:
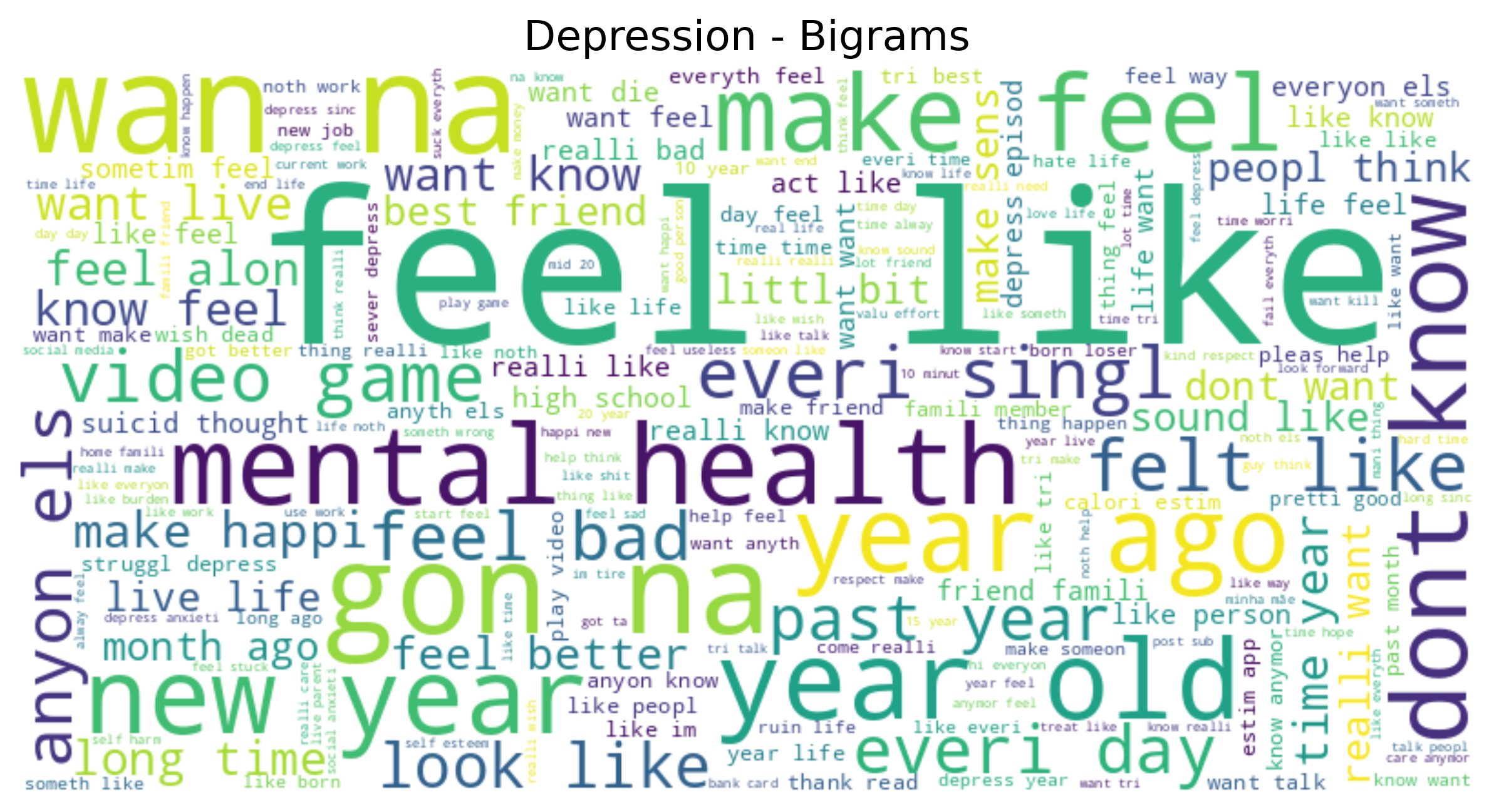

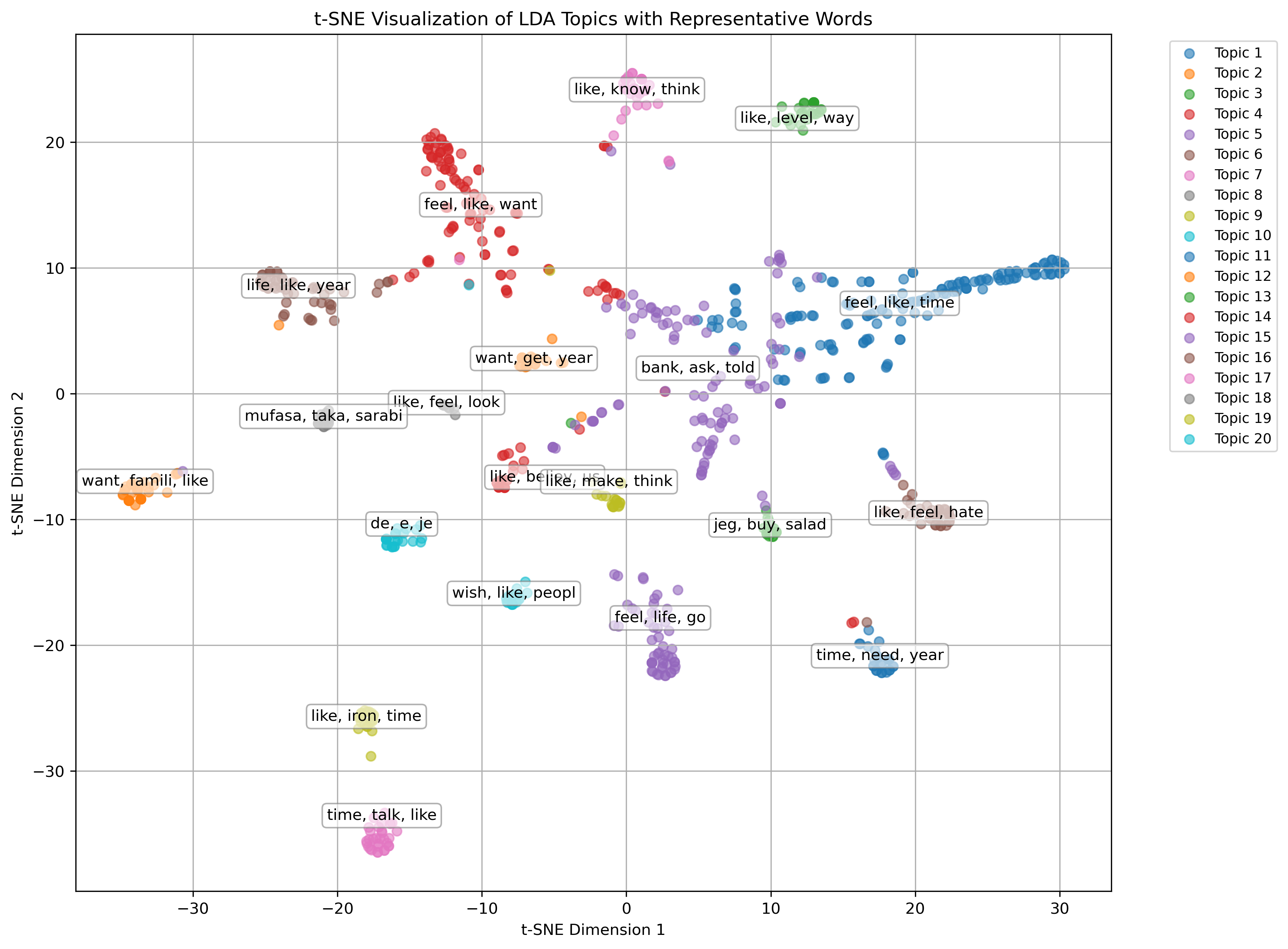
Complete code, data and the replication report are available on GitHub.
References & dependencies
The original paper is:
M. M. Tadesse, H. Lin, B. Xu, and L. Yang, “Detection of Depression-Related Posts in Reddit Social Media Forum,” IEEE Access, vol. 7, pp. 44883–44893, 2019.
Key libraries used in the replication include nltk, scikit-learn, Empath, gensim, and pytest (plus ruff/mypy for linting).